



Nos encanta la Web porque es una red abierta y distribuida que ofrece a todos la libertad y el control para publicar y seguir lo que les importa.
También amamos la web porque ha habilitado una nueva generación de creadores de contenido (Ben Thompson, Bruce Schneier, Tina Eisenberg, Seth Godin, Maria Popova, etc.). Esos pensadores independientes exploran continuamente el límite de lo conocido y comparten ideas perspicaces e inspiradoras con sus comunidades.
Conectar a las personas con las mejores fuentes para los temas que les interesan ha sido fundamental para nuestra misión desde el comienzo de TecnoFans.
Pero el descubrimiento es un problema difícil. La web es orgánica, un reflejo de las necesidades y prioridades cambiantes de la comunidad global. Hay millones de fuentes en miles de temas y todos tenemos un apetito diferente cuando se trata de alimentar nuestras mentes.
Hace unos doce meses, creamos un equipo de aprendizaje automático para ver si los últimos avances en el aprendizaje profundo y el procesamiento del lenguaje natural podrían ayudarnos a resolver este problema.
Hoy, nos complace brindarle una vista previa del resultado de ese trabajo con el lanzamiento de la nueva experiencia de descubrimiento en la aplicación TecnoFans Lab (Experiencia 06).
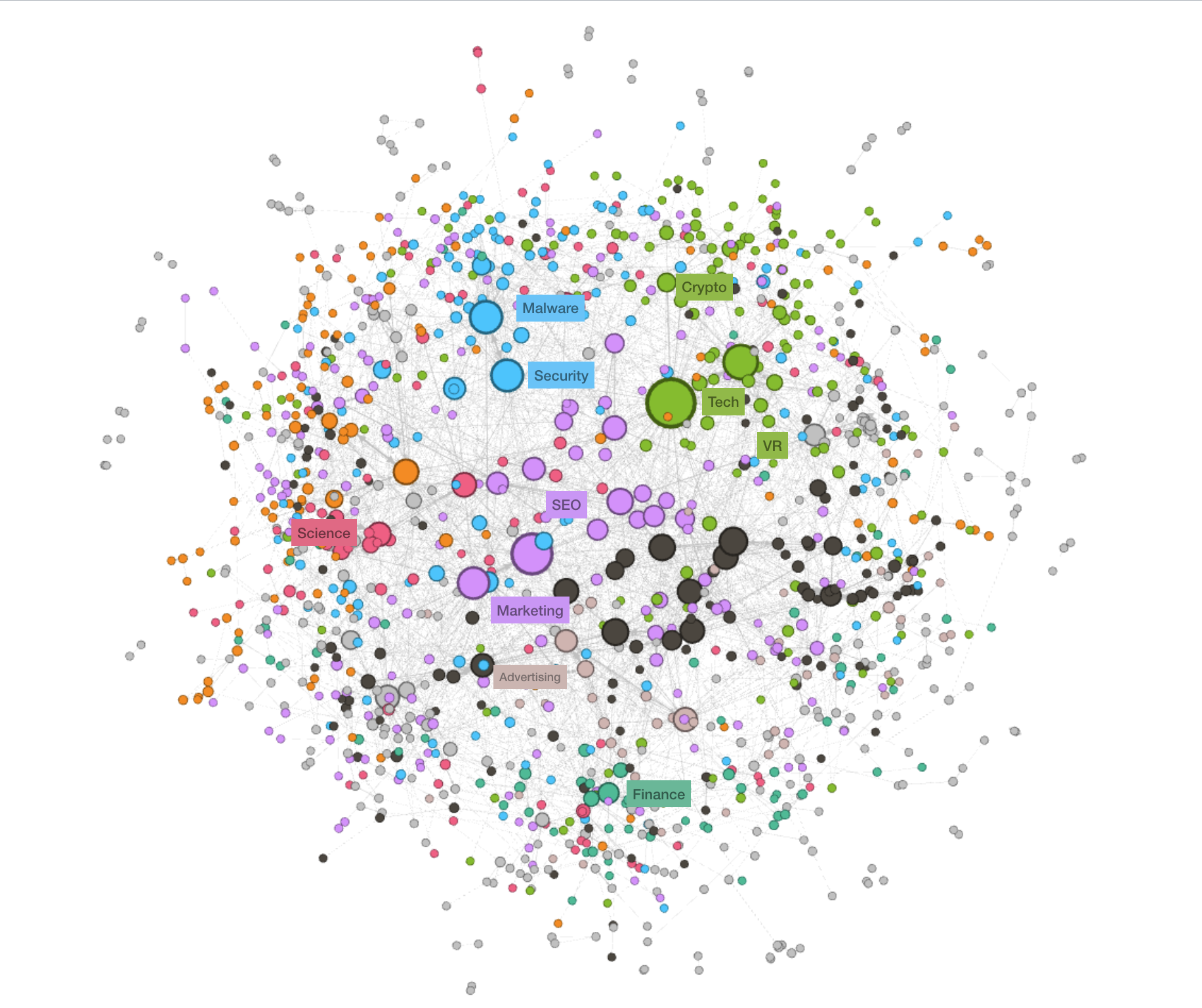
Dos mil temas
El primer desafío de descubrimiento es crear una taxonomía de temas.
Puedes pensar en TecnoFans como un gráfico rico de personas, temas y fuentes. Para construir la taxonomía correcta, comenzamos con los datos sin procesar de todas las fuentes de TecnoFans. Tuvimos que crear un modelo para limpiar, enriquecer y organizar esos datos en una jerarquía de temas. Obtenga más información sobre la ciencia de datos detrás de esto.
El resultado es una red rica e interconectada de dos mil temas en inglés. Y se relaciona bien con la forma en que la gente espera explorar y leer en la Web.
Algunos temas son amplios: tecnología, seguridad, diseño, marketing. Algunos son muy especializados: realidad aumentada, malware, tipografía o SEO.
En la página de inicio de descubrimiento, mostramos treinta temas basados en industrias, tendencias, habilidades o pasiones populares. Puede acceder a todos los temas en TecnoFans a través del cuadro de búsqueda.


Las cincuenta fuentes más interesantes
El segundo desafío de descubrimiento es encontrar las cincuenta fuentes más interesantes que alguien que investigue sobre cualquier tema podría querer seguir.
Clasificar las fuentes es difícil porque no todas las fuentes son iguales. En tecnología, por ejemplo, tiene publicaciones convencionales como The Verge o TechCrunch, voces expertas como Ben Thompson y muchas fuentes ruidosas de la lista B que no agregan mucho valor.
Además, para temas específicos como la realidad virtual, algunas fuentes son específicas de la realidad virtual, mientras que otras cubren una variedad de temas relacionados.
Para resolver este desafío, creamos un modelo que mira las fuentes a través de tres lentes diferentes:
- Conteo de seguidores
- relevancia (qué tan enfocada está la fuente en el tema dado)
- compromiso (un proxy de calidad y atención)
El resultado son nuevas tarjetas de resultados de búsqueda. Puede explorar las cincuenta fuentes más interesantes para un tema determinado y ordenarlas utilizando la lente que sea más importante para usted.

Barrios
Uno de los beneficios del nuevo modelo de temas es que los 2000 temas están organizados en una jerarquía. Esto le facilita acercarse o alejarse y explorar muchos vecindarios diferentes de la Web.

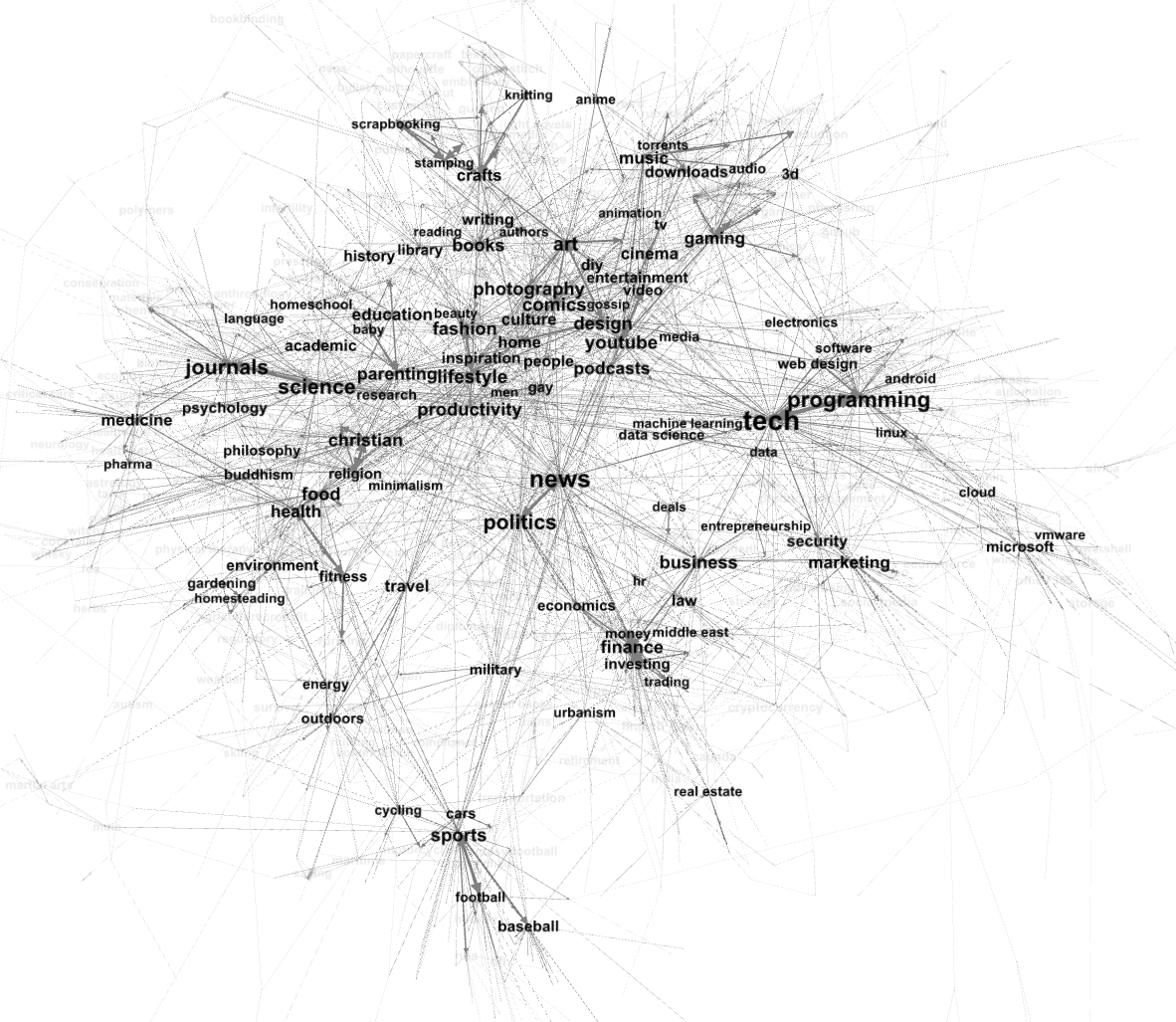
Por ejemplo, desde el tema de la ciberseguridad, puede saltar a una lista de temas relacionados que le permiten profundizar en el malware, la ciencia forense o la privacidad.

Una cosa más…
Hemos investigado mucho durante los últimos cuatro años para comprender cómo las personas descubren nuevas fuentes. Una idea que aprendimos es que las personas a menudo co-leen ciertas fuentes. Por ejemplo, si estás interesado en el arte, el diseño y la cultura pop y sigues a Fubiz, es muy probable que también sigas a Designboom.
Con eso en mente, dedicamos un tiempo a crear un modelo que aprende qué fuentes se leen conjuntamente. La idea es que un usuario pueda ingresar a una fuente que ama y descubrir otra fuente con la que pueda emparejarla.
Puede obtener más información sobre el modelo de aprendizaje automático (lo llamamos feed2vec) que impulsa esta experiencia a través del artículo que Paul publicó aquí.
Como usuario, puede acceder a esta función buscando en la página de descubrimiento una fuente que le guste leer. El resultado será una lista de fuentes que a menudo se leen conjuntamente con esa fuente.


¡Gracias!
Me gustaría agradecer a Paul, Michelle, Mathieu y Aymeric por el gran trabajo de investigación que hicieron para llevar este proyecto de cero a uno. Las personas que han intentado abordar el descubrimiento saben que es un desafío muy difícil y los resultados de este proyecto han sido impresionantes.
También nos gustaría agradecer a la comunidad por participar en el experimento de la Batalla de las Fuentes. Su aportación fue clave para ayudarnos a aprender cómo modelar la clasificación de la fuente. Continuaremos invirtiendo en descubrimiento y esperamos seguir colaborando con usted.
También nos gustaría agradecer a Dan Newman, Daron Brewood, Enrico, Joey, Lior, Paul Adams, Ryan Murphy y Joseph Thornley del laboratorio por revisar una versión anterior de este artículo.
